Sysdig — удобный и функциональный инструмент, дающий администратору широкие возможности для сбора информации о работающей системе.
Установка sysdig.
Быстрый, но не самый правильный на мой скромный взгляд, способ установки sysdig в систему:
# curl -s https://s3.amazonaws.com/download.draios.com/stable/install-sysdig | bash
Однако запускать что-то скачанное из интернета без проверки не есть хорошо, так что мы просто поставим необходимое вручную:
- Идём на страницу установки. Нас интересует раздел Linux там.
- Обращаем внимание на секцию Advanced Install, находим в ней наш дистрибутив и следуем инструкциям.
- Не забываем что EPEL в CentOS 7 ставится командой:
# yum install epel-release
В процессе продвижения по инструкции, будет выполнена установка нужных пакетов, собран модуль ядра для работы sysdig. Возможно, после установки необходимо будет проверить, загружен ли модуль:
# lsmod | grep sysdig sysdig_probe 454565 0
И если нет, загрузить его:
# modprobe sysdig-probe
Работа с sysdig.
sysdig c помощью загруженного модуля ядра фиксирует все события, которые происходят в системе. Для каждого события записываются следующие поля:
- evt.num — номер события;
- evt.time — время события;
- evt.cpu — номер процессора;
- proc.name — имя процесса;
- thread.tid — номер потока;
- evt.dir — направление события (< входящие, > исходящие процессы);
- evt.type — тип события;
- evt.args — аргументы события.
У однопотоковых процессов номер потока (thread.tid) будет такой же как и номер процесса (proc.name). Неотфильтрованный вывод запущенной в работу утилиты имеет следующий формат:
%evt.num %evt.time %evt.cpu %proc.name (%thread.tid) %evt.dir %evt.type %evt.args
И выглядит примерно так:
7848 22:28:55.183177553 0 /usr/bin/spamd (1104) > select 7849 22:28:55.183189166 0 /usr/bin/spamd (1104) > switch next=0 pgft_maj=6 pgft_min=13789 vm_size=276760 vm_rss=63596 vm_swap=0 7850 22:28:55.206607967 0 <NA> (0) > switch next=1572(mysqld) pgft_maj=0 pgft_min=0 vm_size=0 vm_rss=0 vm_swap=0 7851 22:28:55.206617495 0 mysqld (1572) < io_getevents 7852 22:28:55.206623297 0 mysqld (1572) > io_getevents 7853 22:28:55.206628068 0 mysqld (1572) > switch next=1568(mysqld) pgft_maj=0 pgft_min=1 vm_size=922188 vm_rss=78060 vm_swap=0 7854 22:28:55.206630115 0 mysqld (1568) < io_getevents
Разумеется, при необходимости, администратор может отфильтровать только нужные ему поля:
# sysdig proc.name = mysqld # sysdig proc.name = mysqld and evt.cpu = 0
Имеются так же и дополнительные фильтры. Их список можно получить так:
# sysdig -l
А воспользоваться ими аналогичным образом:
# sysdig proc.name = nginx and fd.ip = 46.15.23.10 # sysdig proc.name = nginx and fd.ip = 46.165.230.101 and evt.type = write
Список всех событий и параметров фильтрации вывода, доступен по команде:
# sysdig -L
Так же, администратор может формировать вывод sysdig на своё усмотрение. Делается это, с помощью опции -p, затем можно передать нужный нам фильтр. Например, вывод информации о доступе к директориям пользователем sysadmin
# sysdig -p "username: %user.name ; file: %evt.arg.path" user.name = sysadmin username: sysadmin ; file: /home/sysadmin/web/sysadmin.pm/public_html/index.php username: sysadmin ; file: /home/sysadmin/web/sysadmin.pm/public_html username: sysadmin ; file: /home/sysadmin/web/sysadmin.pm ...
Чизлы.
Кроме описанного выше, в sysdig имеются написанные на Lua небольшие скрипты, которые разработчики называют chisels — с помощью этих скриптов, можно выполнить анализ тех или иных действий в системе. Например, получить время выполнения запросов к процессу сервера БД:
# sysdig -c proc_exec_time proc.name = mysqld proc.duration proc.name proc.args ------------- ------------ -------------------- 180ms mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log --pid-file=/var/run/mariadb/mariadb.pid --socket=/var/lib/mysql/mysql.sock
Или вывести топ соединений в реальном времени:
# sysdig -c topconns
Получить статистику активности дисковой подсистемы:
# sysdig -c topprocs_file
Полный список чизлов выводим командой:
# sysdig -cl
Дамп информации в файл.
При необходимости, вывод работы sysdig утилиты можно записать в файл, затем с получившимся дампом событий можно работать применяя точно такие же фильтры, как если бы работа велась со стандартным выводом. Пишем информацию в файл:
# sysdig -w sysdig.scap # sysdig -n 1000 -w sysdig1k.scap
Затем мы можем этот файл прочитать. В том числе и отфильтровав только нужное:
# sysdig -r sysdig1k.scap # sysdig -r sysdig1k.scap proc.name = fail2ban-server and evt.type = stat
Примеры работы sysdig.
Большое количество примеров доступно в документации, на соответствующей странице. Кроме того, для знакомства с sysdig рекомендую посмотреть вот это короткое видео:
Оптимизируем анализ с сsysdig.
сsysdig — это простой интерфейс в стиле *top утилит, который позволяет упростить и оптимизировать работу с sysdig на сервере, при этом, ничуть не потеряв в функциональности. Просто выполняем команду:
# csysdig
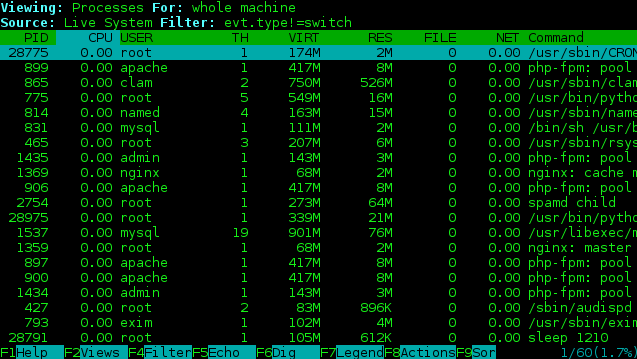
И получаем доступ ко всему что происходит в нашей системе в реальном времени — здесь мы можем указать какую конкретно информацию хотим получать, выполнить фильтрацию по части текста. Мы можем перемещаться непосредственно по списку процессов (стрелки вверх\вниз) и получать подробности нужного нам процесса (Enter для входа, Backspace для возврата), при этом, система сама будет создавать подходящий фильтр, нашего ручного вмешательства не потребуется:

csysdig так же поддерживает передачу параметров при запуске. Например, мы можем сразу же вывести список контейнеров и статистику использования ресурсов ими с помощью команды:
# csysdig -vcontainers
При этом, мы всё так же можем перемещаться по нужным нам процессам. Аналогично, имеется возможность провести анализ заранее записанного дампа:
# csysdig -r sysdig1k.scap
Работа с утилитой отлично показана на этом видео:
Вместо заключения.
Sysdig удобен, не создаёт нагрузки, позволяет работать с контейнерами, сам по себе работает очень быстро и даёт администратору широкий набор инструментов для анализа происходящих в системе процессов. На утилиту обязательно стоит обратить внимание, если ещё не сделали этого раньше, и как минимум, попробовать её в работе.
Очень заманчиво для поиска «узких мест» в системе. Насколько я понял, для работы нужен доступ к ядру ОС. Это значит на виртуальном сервере такое на запустить?
Тогда получается, для виртуальным серверов и домашних компьютеров такое запускать нецелесообразно.
Зависит от типа виртуализации. Если используется, например, KVM, то там ядро гостя от хоста не зависит, и на таком виртуальном сервере утилиту использовать удастся без проблем.