Продолжим, тему парсинга изображений с различных сайтов. Сегодня у нас простой скрипт для парсинга pexels.com. Работает скрипт так:
# ./downloader.pexels.com.sh green 1
green — ключевое слово, по которому мы будем парсить сайт.
1 — страница выдачи с которой мы начнём парсинг.
Результатом работы скрипта будет файл *.url.list со списком ссылок на изображения. Этот список ссылок можно использовать для скачивания wget’ом, например, либо для постинга в канал по описанной ранее схеме.
Немного теории.
Несколько слов о том, как можно парсить сайты с изображениями без постраничной навигации (когда изображения подгружаются при прокрутке). Что бы распарсить такой сайт, нам нужно сделать три важных вещи:
- Понять каким скриптом производится подгрузка, какой делается запрос.
- Определить последнюю страницу (последний экран) выдачи, что бы на нём остановить парсинг.
- Получить нужные URL со страниц сайта.
Находим скрипт.
Для того что бы понять как именно выполняется загрузка делаем следующее:
1. Идём на сайт pexels.com, например, из браузера Сhromium (ну или просто из Google Chrome).
2. Жмём Ctrl+SHift+I, открывая тем самым инструменты для разработчиков и переходим на вкладку Network.
3. В строку поиска на сайте вводим наш ключевик, например clock. Получаем примерно такой результат:
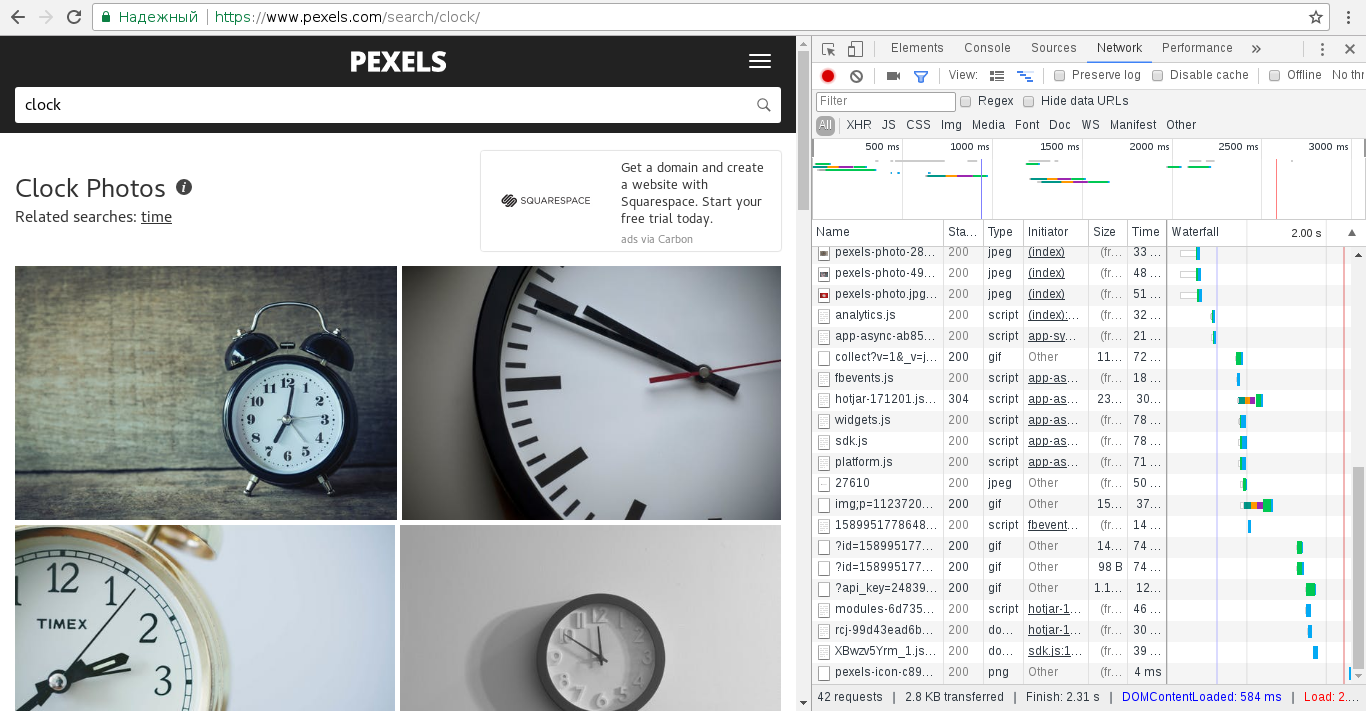
4. В правой части, мы видим список подгружаемых на страницу элементов. Когда мы начнём листать страницу вниз, при загрузке новых изображений запустятся соответствующие скрипты, они-то и будут нужны нам для парсинга. Прокручиваем страницу, получаем очередной список элементов, смотрим на них и находим нужный:

5. Кликаем на элемент, и получаем его подробности, в них нас должен заинтересовать Request URL — это тот самый адрес, который мы будем использовать в скрипте. Отбросим всё лишнее, оставим нужное и получим вот такой URL:
https://www.pexels.com/search/clock/?page=2&format=js
Теперь, перебирая page= мы получаем страницы (а в данном случае код) со ссылками на изображения. Остаётся только автоматизировать перебор страниц и получение прямых ссылок на изображения.
Перебор страниц.
Тут универсального рецепта нет, для каждого сайта нужно находить свой алгоритм.
Для pexels.com я пошёл вот по какому пути… Каждая страница выдачи изображений, содержит ссылку на следующую. На page=1 мы можем найти ссылку на page=2, там на page=3 и так далее. При этом, последняя страница такой ссылки содержать уже не будет. А значит мы берём нужную нам страницу выдачи, проверяем есть ли страница после неё, если есть — переходим, если нет — заканчиваем работу цикла.
Для stocksnap.io, о котором я писал ранее, я применил похожую схему. Там страница содержит параметр .nextPage, мы проверяем наличие этого параметра, и если он есть, на следующую страницу переходим, если нет, завершаем цикл.
Получение URL.
У нас есть всё для автоматизации перебора страниц, всё что нам остаётся — получить адреса изображений со страниц сайта.
В случае со stocksnap.io всё оказалось просто — там я забираю скриптом JSON и просто выдёргиваю нужную переменную, содержащую URL.
C pexels.com дела обстоят сложнее — там весь код написан в одну строку, так что для получения ссылок я сначала выделяю их отдельной строкой, выбираю только нужные мне URL и избавляюсь от дублей. Не исключаю, что это не самый удачный подход, но он показал себя хорошо в моём случае.
Имея алгоритм разбора, всё что остаётся — написать скрипт, который всё это будет делать за нас. Пример такого скрипта для pexels.com можно найти в начале поста, а для stocksnap.io в одной из предыдущих заметок.
Только что проверил, скрин работает, но не наполняет файл *.url.list
[root@cwp download]# ./downloader.pexels.com.sh food 1
—2021-01-01 20:56:37— https://www.pexels.com/search/food/?page=1&format=js
Визначення назви http://www.pexels.com (www.pexels.com)… 104.17.209.102, 104.17.208.102, 2606:4700::6811:d066, …
Встановлення з’єднання з http://www.pexels.com (www.pexels.com)|104.17.209.102|:443… з’єднано.
HTTP-запит надіслано, очікуємо на відповідь… 403 Forbidden
2021-01-01 20:56:38 ПОМИЛКА 403: Forbidden.